Lagrange Multipliers
Consider the unconstrained optimization problem
x∈Rnmin f(x)
The first criteria for x∗ to be a local minima is that the gradient ∇f(x∗) that represents the
direction of steepest ascent, becomes zero.
This means, in an unrestricted space (absence of constraints) where the point x can move in any direction
in Rn in order to minimize the function, has no where to go. How to interpret the same thing in
a constrained optimization problem? In this article I will try to give an intuition for this problem with the
help of widely used Lagrange multipliers.
Consider the following optimization problem with equality constraint
x∈Rnmin f(x)s.t. hi(x)=0 i=1,2,⋯,p
Now, the decision set is restricted. The point x can not move freely in Rn.
1. One Equality Constraint
For simplicity, let us only consider an example with only one constraint h.
x∈Rnmin x2+y2+xys.t. x+y−1=0
The solution to this problem attains at A =(21,21)(DIY) as shown in the Figure 1.
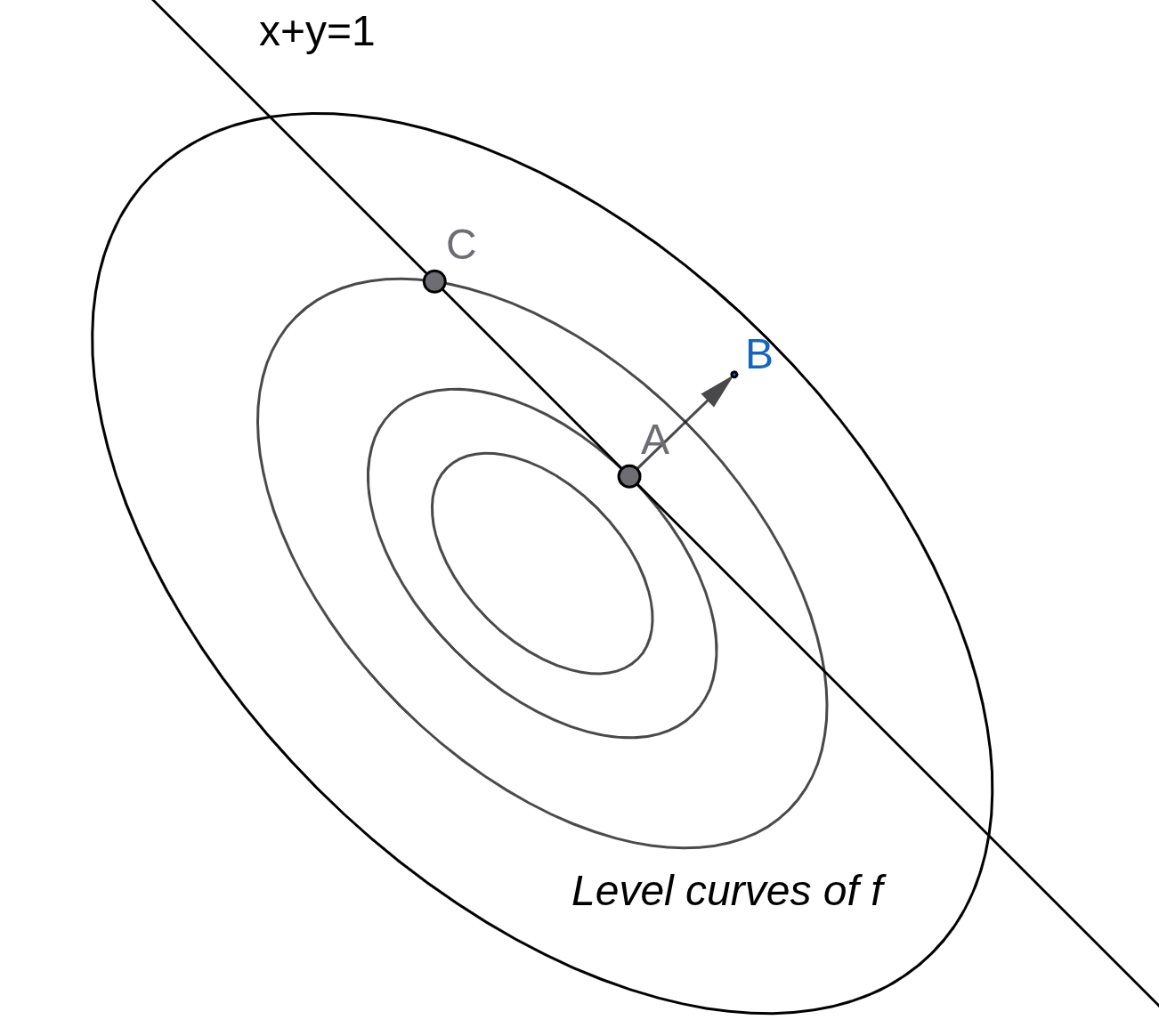
Figure 1: Contour visualization
One important thing to note in the above figure, at optimal point (A), the constraint line is a tangent to the level curve.
If the constraint was non-linear, at the point of optima, the both f and g will have a common tangent.
The intuition is that at a different feasible point say C, where the level curve intersects the constraint, if
the function f moves towards A, it can still reduce its value. Therefore, C can not be a optimal point.
This fact becomes more clear when we look at the normal (ray AB) to both the curves at the point A. The normal to
the level curve and the constranints are parallel i.e.,∇xf(A)=μ∇xg(A).
Notice, that the gradient of f at A is not zero but the direction of steepest ascent (take negative and it becomes descent)
is parallel to the normal to the gradient. Therefore, any step toward that direction will lead to constraint violation.
Based on the equation given in the above equation, we define the lagrangian function as follows
L(x,μ)≐f(x)+μg
where μ is a called a Lagrange multiplier. In L,μ acts as a penalty term for violating g. We wish to stay on the constraint set g and μ acts as a pushback, ensuring that
any movement away from g becomes undesirable in L. We solve the Lagrangian wrtx,μ, and the resultant x∗ is also optimal point
of the original problem.
2. Many Equality Constraints
what happens when there are two equality constraint g1,g2 in the problem? A point of optima
need to satisfy both the constraints. Like the one constraint case, does the level curve and two
constraints share the same tangent at the point of optima? What about the normal to the level curve
at an optimal point? Let us take an example by adding an new constraint g2:x2+y2=4 to our
previous problem. The solution attains at [1.82,−0.82]T as shown in the figure below.
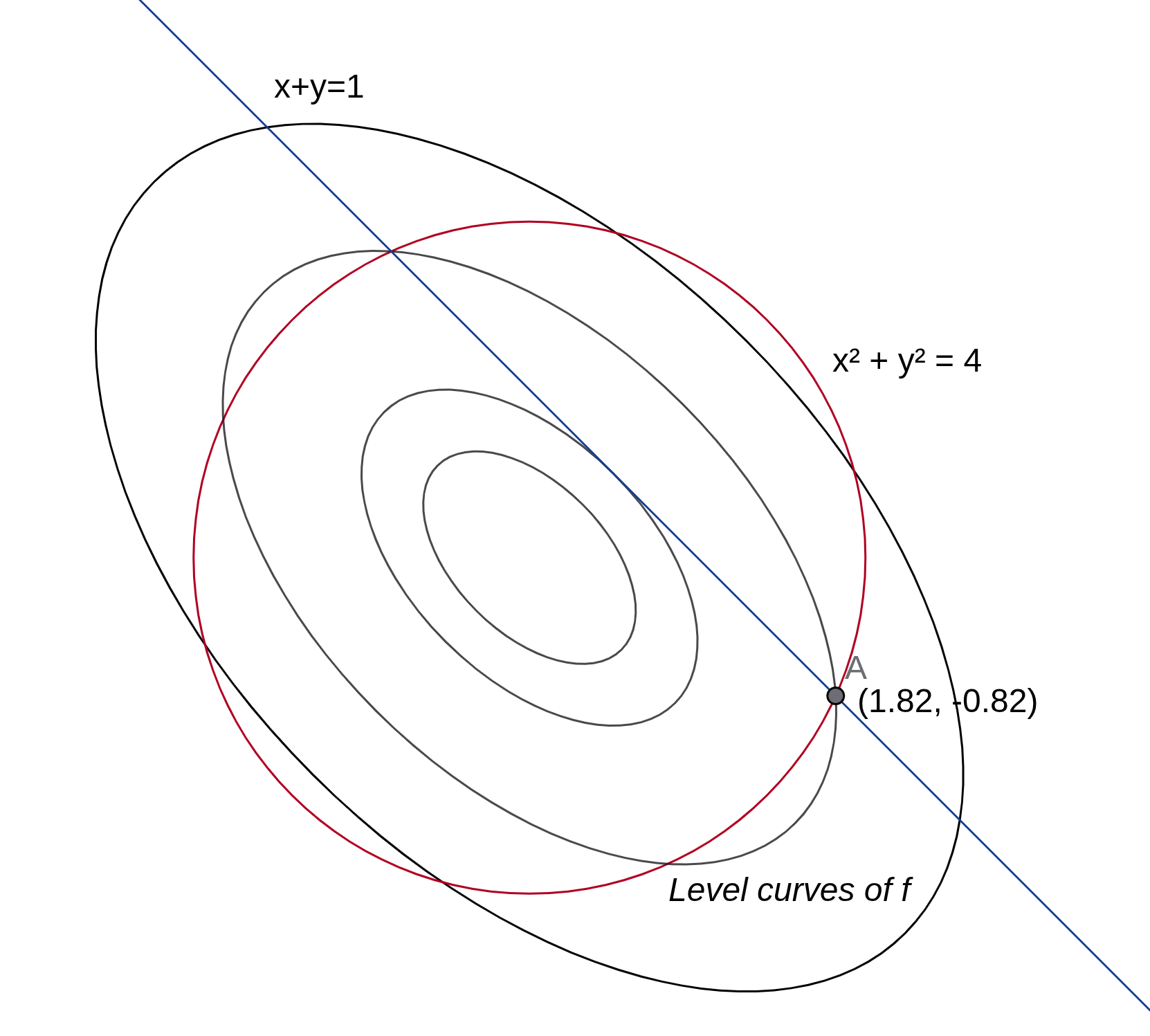
Figure 1: Contour visualization
One can see that the gradient of the objective function is not zero at A. Also, the tangent to the
level curve, g1 and g2 are not parallel anymore. The observations about the normal to the level
curve is not the same but can be extended with increasing number of constraints.
The idea was that
at the point of optima, the gradient should not be able to take any local step along a vector that
can minimize further. Such a vector if exists (non zero) should be perpendicular to the constraints
so that any step along that direction takes f out of feasible region. Therefore, gradient is
spanned by the normals to the constraints, i.e. ∇xf(A)=μ1∇xg1(A)+μ2∇xg2(A).
Therefore, extending similar argument, the Lagrangian for p equality constraints problem can be written as
L(x,μ)≐f(A)+i=1∑pμigi
3. Inequality Constraints
Inequality constraints gi(x)≤0 is called inactive x if gi(x)<0. This is called inactive because it
allows local movement along all possible direction around x without violating the constraint. Since, it allows local
movement along all possible direction, it does not influence the optimality of the function. Therefore, while solving
a optimization problem, inactive constraints are ‘ignored’. When gi(x)=0, it mostly behave like a equality constraint
with a condition that the corresponding Lagrange multiplier λi is non-negative. This is because, at an optimal
point x∗,g(x∗)=0 and from the Lagrangian
∇xf(x∗)+λ∇g(x∗)⇒∇xf(x∗)=0=−λ∇g(x∗)
∇g points outside the feasible region, therefore, if λ<0 it encourages f to violate the constraint, which
is not a expected behaviour. The function of a constraint is to push back the function not pull outside the feasible region.
For details on the role of Lagrangian multipliers in optimization of an NLP (Non-linear Programming) see the KKT condition
(Write a new article on KKT conditions).
4. Interpreting Lagrange Multipliers
Lagrange multipliers are interpreted as an amount force the constraint applies at the optimum. It tells about the
sensitivity of a constraint. How much does the objective function change with a unit change in the corresponding
constraint. To form a mental model, if a constraint is seen as a blockade, the corresponding Lagrange multiplier
tells how strongly the constraint is blocking the objective function. It also represents the importance of a
constraint in shaping the gradient vector ∇f.